Data Storage: Setting up S3
Last updated on 2024-11-05 | Edit this page
Overview
Questions
- How can I store and manage data effectively in AWS for SageMaker workflows?
- What are the best practices for using S3 versus EC2 storage for machine learning projects?
Objectives
- Explain data storage options in AWS for machine learning projects.
- Describe the advantages of S3 for large datasets and multi-user workflows.
- Outline steps to set up an S3 bucket and manage data within SageMaker.
Step 1: Data storage
Hackathon Attendees: All data uploaded to AWS must relate to your specific Kaggle challenge, except for auxiliary datasets for transfer learning or pretraining. DO NOT upload any restricted or sensitive data to AWS.
Options for storage: EC2 Instance or S3
When working with SageMaker and other AWS services, you have options for data storage, primarily EC2 instances or S3.
What is an EC2 instance?
An Amazon EC2 (Elastic Compute Cloud) instance is a virtual server environment where you can run applications, process data, and store data temporarily. EC2 instances come in various types and sizes to meet different computing and memory needs, making them versatile for tasks ranging from light web servers to intensive machine learning workloads. In SageMaker, the notebook instance itself is an EC2 instance configured to run Jupyter notebooks, enabling direct data processing.
When to store data directly on EC2
Using an EC2 instance for data storage can be useful for temporary or small datasets, especially during processing within a Jupyter notebook. However, this storage is not persistent; if the instance is stopped or terminated, the data is erased. Therefore, EC2 is ideal for one-off experiments or intermediate steps in data processing.
Limitations of EC2 storage
- Scalability: EC2 storage is limited to the instance’s disk capacity, so it may not be ideal for very large datasets.
- Cost: EC2 storage can be more costly for long-term use compared to S3.
- Data Persistence: EC2 data may be lost if the instance is stopped or terminated, unless using Elastic Block Store (EBS) for persistent storage.
What is an S3 bucket?
Storing data in an S3 bucket is generally preferred
for machine learning workflows on AWS, especially when using SageMaker.
An S3 bucket is a container in Amazon S3 (Simple Storage Service) where
you can store, organize, and manage data files. Buckets act as the
top-level directory within S3 and can hold a virtually unlimited number
of files and folders, making them ideal for storing large datasets,
backups, logs, or any files needed for your project. You access objects
in a bucket via a unique S3 URI (e.g.,
s3://your-bucket-name/your-file.csv), which you can use to
reference data across various AWS services like EC2 and SageMaker.
Benefits of using S3 (recommended for SageMaker and ML workflows)
For flexibility, scalability, and cost efficiency, store data in S3 and load it into EC2 as needed. This setup allows:
- Scalability: S3 handles large datasets efficiently, enabling storage beyond the limits of an EC2 instance’s disk space.
- Cost efficiency: S3 storage costs are generally lower than expanding EC2 disk volumes. You only pay for the storage you use.
- Separation of storage and compute: You can start and stop EC2 instances without losing access to data stored in S3.
- Integration with AWS services: SageMaker can read directly from and write back to S3, making it ideal for AWS-based workflows.
- Easy data sharing: Datasets in S3 are easier to share with team members or across projects compared to EC2 storage.
- Cost-effective data transfer: When S3 and EC2 are in the same region, data transfer between them is free.
Recommended approach: S3 buckets
Hackathon attendees: When you setup your bucket for your actual project, note that you will only need one bucket for your whole team. Team members will have the proper permissions to access buckets on our shared account.
Summary steps to access S3 and upload your dataset
- Log in to AWS Console and navigate to S3.
- Create a new bucket or use an existing one.
- Upload your dataset files.
- Use the object URL to reference your data in future experiments.
Detailed procedure
-
Sign in to the AWS Management Console
- Log in to AWS Console using your credentials.
-
Navigate to S3
- Type “S3” in the search bar
- Protip: select the star icon to save S3 as a bookmark in your AWS toolbar
- Select S3 - Scalable Storage in the Cloud
-
Create a new bucket
- Click Create Bucket and enter a unique name, and
note that bucket name must not contain uppercase characters.
Hackathon participants: Use the following convention
for your bucket name:
teamname_datasetname(e.g.,myawesometeam-titanic). -
Region: Leave as is (likely
us-east-1(US East N. Virginia)) - Access Control: Disable ACLs (recommended).
- Public Access: Turn on “Block all public access”.
- Versioning: Disable unless you need multiple versions of objects.
-
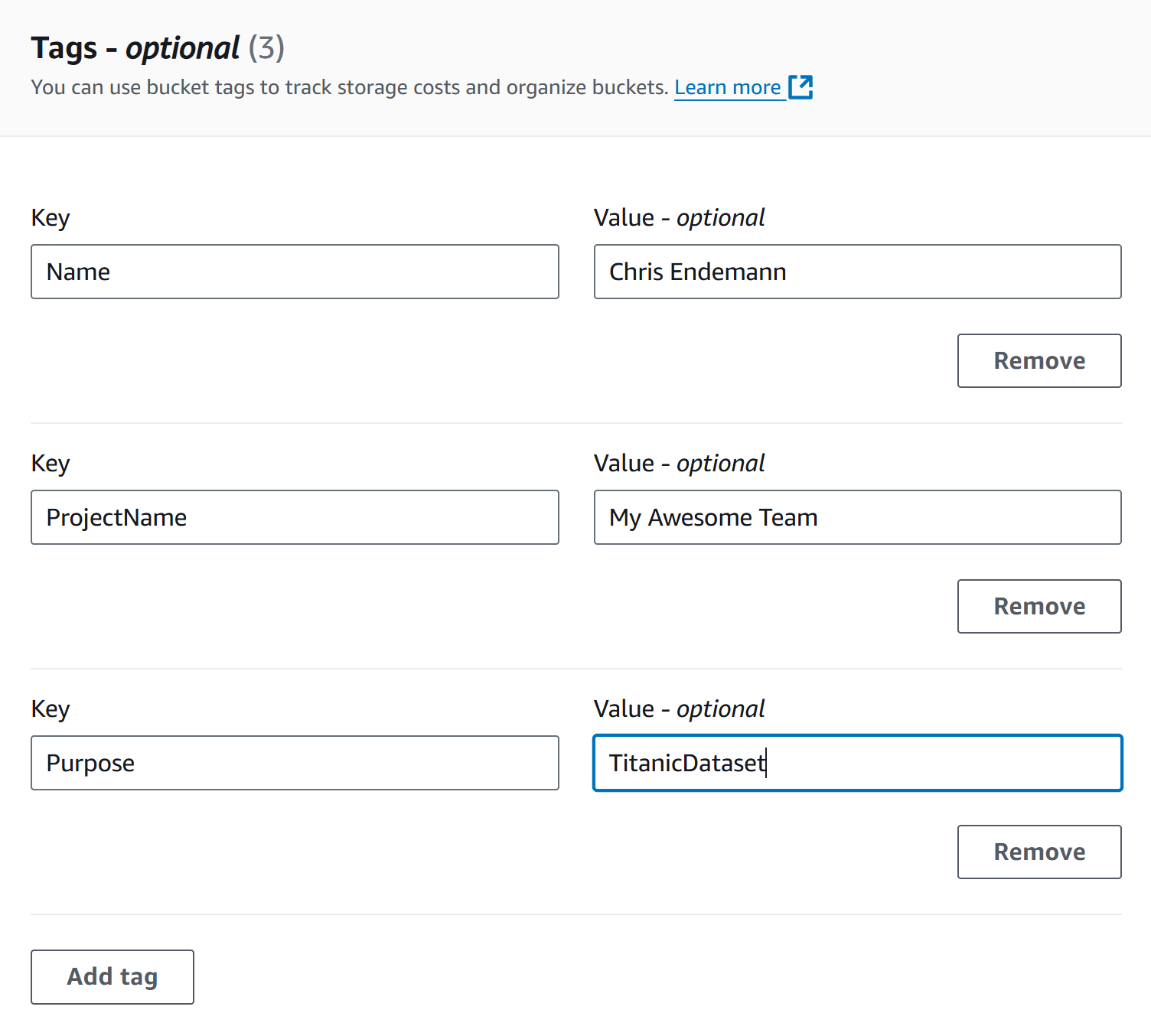
Tags: Adding tags to your S3 buckets is a great way
to track project-specific costs and usage over time, especially as data
and resources scale up. While tags are required for hackathon
participants, we suggest that all users apply tags to easily identify
and analyze costs later. Hackathon participants: Use
the following convention for your bucket name
- Name: Your Name
- ProjectName: Your team’s name
-
Purpose: Dataset name (e.g., titanic if you’re
following along with this workshop)
- Click Create Bucket at the bottom once everything above has been configured
- Click Create Bucket and enter a unique name, and
note that bucket name must not contain uppercase characters.
Hackathon participants: Use the following convention
for your bucket name:
-
Edit bucket policy Once the bucket is created, you’ll be brought to a page that shows all of your current buckets (and those on our shared account). We’ll have to edit our bucket’s policy to allow ourselves proper access to any files stored there (e.g., read from bucket, write to bucket). To set these permissions…
- Click on the name of your bucket to bring up additional options and settings.
- Click the Permissions tab
- Scroll down to Bucket policy and click Edit. Paste the following policy, editing the bucket name “myawesometeam-titanic” to reflect your bucket’s name
JSON
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::183295408236:role/ml-sagemaker-use"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::myawesometeam-titanic",
"arn:aws:s3:::myawesometeam-titanic/*"
]
}
]
}For hackathon attendees, this policy grants the
ml-sagemaker-use IAM role access to specific S3 bucket
actions, ensuring they can use the bucket for reading, writing,
deleting, and listing parts during multipart uploads. Attendees should
apply this policy to their buckets to enable SageMaker to operate on
stored data.
General guidance for setting up permissions outside the hackathon
For those not participating in the hackathon, it’s essential to
create a similar IAM role (such as ml-sagemaker-use) with
policies that provide controlled access to S3 resources, ensuring only
the necessary actions are permitted for security and
cost-efficiency.
Create an IAM role: Set up an IAM role for SageMaker to assume, with necessary S3 access permissions, such as
s3:GetObject,s3:PutObject,s3:DeleteObject, ands3:ListMultipartUploadParts, as shown in the policy above.Attach permissions to S3 buckets: Attach bucket policies that specify this role as the principal, as in the hackathon example.
More information: For a detailed guide on setting up roles and policies for SageMaker, refer to the AWS SageMaker documentation on IAM roles and policies. This resource explains role creation, permission setups, and policy best practices tailored for SageMaker’s operations with S3 and other AWS services.
This setup ensures that your SageMaker operations will have the access needed without exposing the bucket to unnecessary permissions or external accounts.
-
Upload files to the bucket
- Navigate to the Objects tab of your bucket, then Upload.
-
Add Files (e.g.,
titanic_train.csv,titanic_test.csv) and click Upload to complete.
-
Take note of S3 URI for your data
- After uploading, click on a file to find its Object
URI (e.g.,
s3://titanic-dataset-test/test.csv). We’ll use this URI to load data into SageMaker later.
- After uploading, click on a file to find its Object
URI (e.g.,
S3 bucket costs
S3 bucket storage incurs costs based on data storage, data transfer, and request counts.
Storage costs
- Storage is charged per GB per month. Typical: Storing 10 GB costs approximately $0.23/month in S3 Standard (us-east-1).
- Pricing Tiers: S3 offers multiple storage classes (Standard, Intelligent-Tiering, Glacier, etc.), with different costs based on access frequency and retrieval times. Standard S3 fits most purposes. If you’re curious about other tiers, refer to AWS’s S3 Pricing Information.
- To calculate specific costs based on your needs, storage class, and region, refer to AWS’s S3 Pricing Information.
Data transfer costs
- Uploading data to S3 is free.
- Downloading data (out of S3) incurs charges (~$0.09/GB). Be sure to take note of this fee, as it can add up fast for large datasets.
- In-region transfer (e.g., S3 to EC2) is free, while cross-region data transfer is charged (~$0.02/GB).
Request costs
- GET requests are $0.0004 per 1,000 requests. In the context of Amazon S3, “GET” requests refer to the action of retrieving or downloading data from an S3 bucket. Each time a file or object is accessed in S3, it incurs a small cost per request. This means that if you have code that reads data from S3 frequently, such as loading datasets repeatedly, each read operation counts as a GET request.
Challenge Exercise: Calculate Your Project’s Data Costs
Estimate the total cost of storing your project data in S3 for one month, using the following dataset sizes and assuming:
- Storage duration: 1 month
- Storage region: us-east-1
- Storage class: S3 Standard
- Data will be retrieved 100 times for model training
(
GETrequests) - Data will be deleted after the project concludes, incurring data retrieval and deletion costs
Dataset sizes to consider:
- 1 GB
- 10 GB
- 100 GB
- 1 TB
Hints
- S3 storage cost: $0.023 per GB per month (us-east-1)
- Data transfer cost (retrieval/deletion): $0.09 per GB (us-east-1 out to internet)
-
GETrequests cost: $0.0004 per 1,000 requests (each model training will incur oneGETrequest)
Check the AWS S3 Pricing page for more details.
Using the S3 Standard rate in us-east-1:
-
1 GB:
- Storage: 1 GB * $0.023 = $0.023
-
Retrieval/Deletion: 1 GB * $0.09 = $0.09
-
GET Requests: 100 requests * $0.0004 per 1,000 =
$0.00004
- Total Cost: $0.11304
-
10 GB:
- Storage: 10 GB * $0.023 = $0.23
-
Retrieval/Deletion: 10 GB * $0.09 = $0.90
-
GET Requests: 100 requests * $0.0004 per 1,000 =
$0.00004
- Total Cost: $1.13004
-
100 GB:
- Storage: 100 GB * $0.023 = $2.30
-
Retrieval/Deletion: 100 GB * $0.09 = $9.00
-
GET Requests: 100 requests * $0.0004 per 1,000 =
$0.00004
- Total Cost: $11.30004
-
1 TB (1024 GB):
- Storage: 1024 GB * $0.023 = $23.55
-
Retrieval/Deletion: 1024 GB * $0.09 = $92.16
-
GET Requests: 100 requests * $0.0004 per 1,000 =
$0.00004
- Total Cost: $115.71004
These costs assume no additional request charges beyond those for
retrieval, storage, and GET requests for training.
Removing unused data
Choose one of these options:
Option 1: Delete data only
- When to Use: You plan to reuse the bucket.
-
Steps:
- Go to S3, navigate to the bucket.
- Select files to delete, then Actions > Delete.
-
CLI (optional):
!aws s3 rm s3://your-bucket-name --recursive
Option 2: Delete the S3 bucket entirely
- When to Use: You no longer need the bucket or data.
-
Steps:
- Select the bucket, click Actions > Delete.
- Type the bucket name to confirm deletion.
Deleting the bucket stops all costs associated with storage, requests, and data transfer.
Key Points
- Use S3 for scalable, cost-effective, and flexible storage.
- EC2 storage is fairly uncommon, but may be suitable for small, temporary datasets.
- Track your S3 storage costs, data transfer, and requests to manage expenses.
- Regularly delete unused data or buckets to avoid ongoing costs.